2021-05-30
828

NoSql入门和概述-Redis安装部署
1 NoSql入门和概述
1.1入门概述
1.1.1为什么用nosql
1.1.2是什么
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”
泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。
1.1.3能干嘛
易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。
数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。
大数据量高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。
这得益于它的无关系性,数据库的结构简单。
一般MySQL使用Query Cache,每次表的更新Cache就失效,是一种大粒度的Cache,在针对web2.0的交互频繁的应用,Cache性能不高。而NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多了
多样灵活的数据模型
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦
传统RDBMS VS NOSQL
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式 -键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
1.1.4ACID和CAP
ACID
A (Atomicity) 原子性 C (Consistency) 一致性 I (Isolation) 独立性 D (Durability) 持久性
CAP
C:Consistency(强一致性) A:Availability(可用性) P:Partition tolerance(分区容错性)
2Redis安装配置
2.1Windows环境安装及操作
2.1.1Windows下安装
下载地址:https://github.com/MSOpenTech/redis/releases
Redis 支持 32 位和 64 位。这个需要根据你系统平台的实际情况选择,这里我们下载 Redis-x64-xxx.zip压缩包到 C 盘,解压后,将文件夹重新命名为 redis。
2.1.2Windows 启动服务
打开一个 cmd 窗口
使用cd命令切换目录到 C:\redis 运行 redis-server.exe redis.windows.conf
如果想方便的话,可以把 redis 的路径加到系统的环境变量里,这样就省得再输路径了,后面的那个 redis.windows.conf 可以省略,如果省略,会启用默认的。输入之后,会显示如下界面:

这时候另启一个cmd窗口,原来的不要关闭,不然就无法访问服务端了。
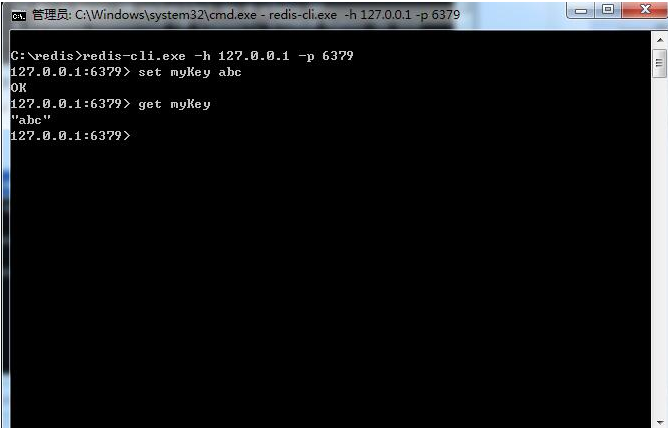
2.1.3命令窗口简单测试
切换到redis目录下运行 redis-cli.exe -h 127.0.0.1 -p 6379 。
设置键值对 set myKey abc
取出键值对 get myKey
2.2Linux环境安装及操作
2.2.1Linux下安装
下载地址:https://redis.io/download
教程使用 redis-3.2.9.tar.gz 32位
拷贝 redis-3.2.9.tar.gz 到 Linux hduser 目录下,如下图

通过cd 到 hduser目录下,使用tar -zxvf redis-3.2.9.tar.gz 命令解压
 解压完后的文件
解压完后的文件
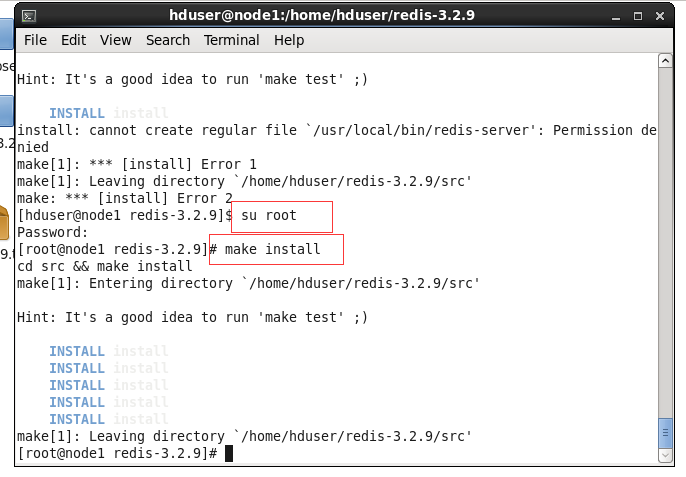
 cd 进入到 redis-3.2.9 解压目录 先执行make,在执行一次make install
cd 进入到 redis-3.2.9 解压目录 先执行make,在执行一次make install

2.2.2修改redis配置文件
Redis 的配置文件位于 Redis 安装目录下,文件名为 redis.conf
/home/hduser/ redis-3.2.9/redis.conf
 可以先拷贝到Windows下然后修改完在覆盖到linux上。也可直接通过vi修改文件信息。
可以先拷贝到Windows下然后修改完在覆盖到linux上。也可直接通过vi修改文件信息。
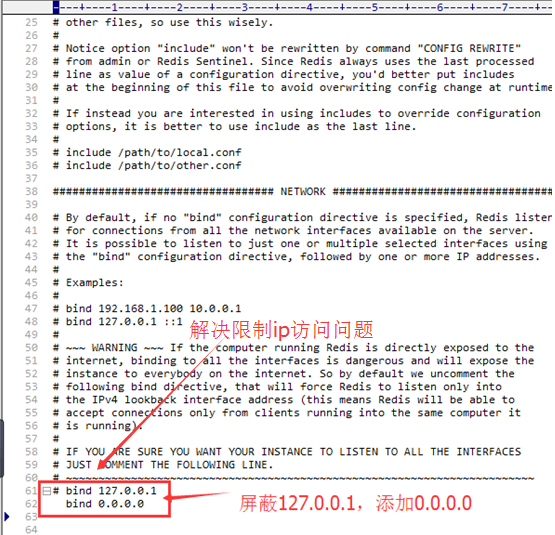
需要修改的地方有两处:

2.2.3参数说明
redis.conf 配置项说明如下:
1.Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
daemonize no
- 当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定
pidfile /var/run/redis.pid
- 指定Redis监听端口,默认端口为6379,作者在自己的一篇博文中解释了为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字
port 6379
- 绑定的主机地址
bind 127.0.0.1
5.当客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
timeout 300
- 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose
loglevel verbose
- 日志记录方式,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
logfile stdout
- 设置数据库的数量,默认数据库为0,可以使用
SELECT <dbid>命令在连接上指定数据库id
databases 16
- 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
save <seconds> <changes>
Redis默认配置文件中提供了三个条件:
save 900 1
save 300 10
save 60 10000
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
10.指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes
- 指定本地数据库文件名,默认值为dump.rdb
dbfilename dump.rdb
- 指定本地数据库存放目录 dir ./
- 设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
slaveof <masterip> <masterport>
- 当master服务设置了密码保护时,slav服务连接master的密码
masterauth
- 设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过
AUTH <password>命令提供密码,默认关闭 requirepass foobared - 设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息 maxclients 128
- 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
maxmemory
- 指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no appendonly no
- 指定更新日志文件名,默认为appendonly.aof appendfilename appendonly.aof
- 指定更新日志条件,共有3个可选值: no:表示等操作系统进行数据缓存同步到磁盘(快) always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全) everysec:表示每秒同步一次(折衷,默认值) appendfsync everysec
- 指定是否启用虚拟内存机制,默认值为no,简单的介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析Redis的VM机制) vm-enabled no
- 虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享 vm-swap-file /tmp/redis.swap
- 将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0 vm-max-memory 0
- Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不 确定,就使用默认值 vm-page-size 32
- 设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存。 vm-pages 134217728
- 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4 vm-max-threads 4
- 设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启 glueoutputbuf yes
- 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法 hash-max-zipmap-entries 64 hash-max-zipmap-value 512
- 指定是否激活重置哈希,默认为开启(后面在介绍Redis的哈希算法时具体介绍) activerehashing yes
- 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件 include /path/to/local.conf
2.2.4Linux启动server服务
首先需要cd 切换到redis安装目录 /usr/local/bin
 启动命令:./redis-server /home/hduser/redis-3.2.9/redis.conf
启动命令:./redis-server /home/hduser/redis-3.2.9/redis.conf

2.2.5Linux 启动客户端程序
首先需要cd 切换到redis安装目录 /usr/local/bin
./redis-cli
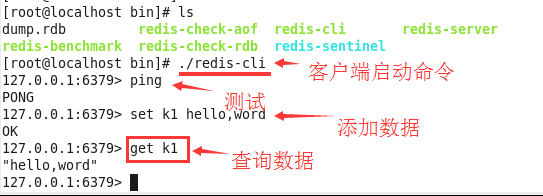 恭喜你已经成功安装好redis服务。
恭喜你已经成功安装好redis服务。
2.2.6防火墙命令
- 重启后生效
开启: chkconfig iptables on
关闭: chkconfig iptables off
- 即时生效,重启后失效
开启: service iptables start
关闭: service iptables stop
2.3Redis密码安全
我们可以通过 redis 的配置文件设置密码参数,这样客户端连接到 redis 服务就需要密码验证,这样可以让你的 redis 服务更安全。
2.3.1设置密码(只能在该次服务生效,重启失效)
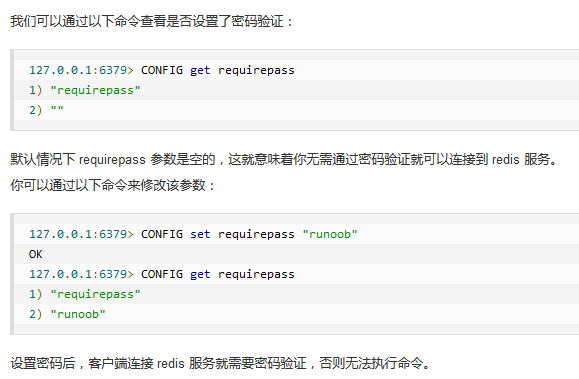
2.3.2语法

2.3.3实例

2.3.4修改配置文件(永久生效)
修改redis.conf配置文件


2.4五大数据类型
2.4.1字符串(String)

2.4.2哈希(Hash)
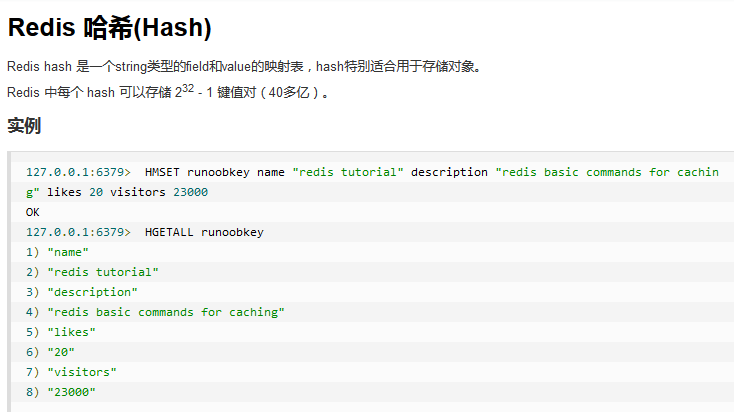
2.4.3列表(List)

2.4.4集合(Set)

2.4.5有序集合(sorted set)

2.5Windows客户端工具

2.6Redis常用命令
Redis 命令用于在 redis 服务上执行操作 要在 redis 服务上执行命令需要一个 redis 客户端
下面介绍操作 Redis 的常用命令:
1.redis-cli:Shell 命令行下启动 Redis 客户端工具
2.set(set key value): 之前介绍过 Redis 是以 key-value 的格式来存储数据的,set 命令就是设置 key 对应 的 value 值(string 类型),设置成功,返回 1;失败,返回 0。
3.get(get key):通过 key 值获取其对应的 value 值,若不存在,则返回 nil。
4.exists(exists key):判断指定的 key 是否存在,存在返回 1,不存在返回 0。
5.del(key):删除一个指定 key。
6.quit:关闭连接。
7.info:查看 Redis 的相关信息。
8.flushdb:清空当前库。
9.flushall:清空所有数据库。
2.6.1数据库数量
默认16个数据库,类似数组下标从零开始,初始默认使用0号库 Select 命令切换数据库
Select 0
2.6.2查看当前数据库的key的数量
DBSIZE
Keys *
2.6.3删除库
清空当前库
FLUSHDB
通杀全部库
FLUSHALL
3Java使用redis
3.1连接到 redis 服务
3.1.1导入jar包

3.1.2示例代码
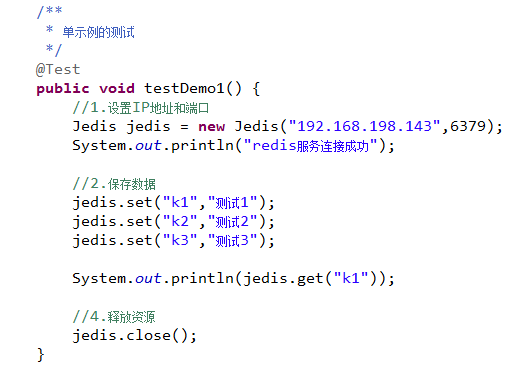
3.2SSM与redis集成

3.2.1实现接口org.apache.ibatis.cache.Cache
package cn.bdqn.redis;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
import org.apache.ibatis.cache.Cache;
import org.apache.ibatis.logging.Log;
import org.apache.ibatis.logging.LogFactory;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class RedisCache implements Cache{
private static Log logger = LogFactory.getLog(RedisCache.class);
private Jedis redisClient = createClient();
/** The ReadWriteLock. */
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private String id;
public RedisCache(final String id) {
if (id == null) {
throw new IllegalArgumentException("Cache instances require an ID");
}
logger.debug(">>>>>>>>>>>>>>>>>>>>>>>>MybatisRedisCache:id=" + id);
this.id = id;
}
public String getId() {
return this.id;
}
public int getSize() {
return Integer.valueOf(redisClient.dbSize().toString());
}
public void putObject(Object key, Object value) {
logger.debug(">>>>>>>>>>>>>>>>>>>>>>>>putObject:" + key + "=" + value);
redisClient.set(SerializeUtil.serialize(key.toString()), SerializeUtil
.serialize(value));
//设置超时时间
//redisClient.expire(SerializeUtil.serialize(key.toString()),10);
}
public Object getObject(Object key) {
// System.out.println("Object key>> " + key);
Object value = SerializeUtil.unserialize(redisClient.get(SerializeUtil
.serialize(key.toString())));
logger.debug(">>>>>>>>>>>>>>>>>>>>>>>>getObject:" + key + "=" + value);
return value;
}
public Object removeObject(Object key) {
System.out.println("removeObject>>>>>key>>>" + key);
return redisClient.expire(SerializeUtil.serialize(key.toString()), 0);
}
public void clear() {
redisClient.flushDB();
}
public ReadWriteLock getReadWriteLock() {
return readWriteLock;
}
protected static Jedis createClient() {
try {
JedisPool pool = new JedisPool(new JedisPoolConfig(),
"192.168.198.143",6379);
return pool.getResource();
} catch (Exception e) {
e.printStackTrace();
}
throw new RuntimeException("初始化连接池错误");
}
}
3.2.2定义序列化工具类
package cn.bdqn.redis;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class SerializeUtil {
public static byte[] serialize(Object object) {
ObjectOutputStream oos = null;
ByteArrayOutputStream baos = null;
try {
// 序列化
baos = new ByteArrayOutputStream();
oos = new ObjectOutputStream(baos);
oos.writeObject(object);
byte[] bytes = baos.toByteArray();
return bytes;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public static Object unserialize(byte[] bytes) {
if (bytes == null)
return null;
ByteArrayInputStream bais = null;
try {
// 反序列化
bais = new ByteArrayInputStream(bytes);
ObjectInputStream ois = new ObjectInputStream(bais);
return ois.readObject();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
3.2.3编写LoggingRedisCache
package cn.bdqn.redis;
import org.apache.ibatis.cache.decorators.LoggingCache;
public class LoggingRedisCache extends LoggingCache{
public LoggingRedisCache(String id) {
super(new RedisCache(id));
}
}
3.2.4在mapper.xml配置缓存
<cache eviction="LRU" type="cn.bdqn.redis.LoggingRedisCache"/>
开启二级缓存,默认是不开启的
<setting name="cacheEnabled" value="true" />

3.2.5实体类必须序列化

3.2.6测试

4Redis的复制(Master/Slave)
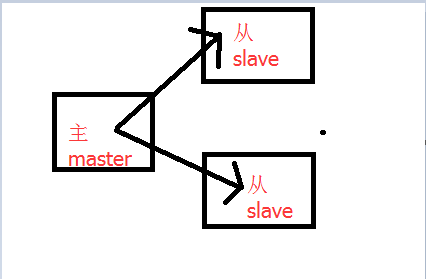
4.1是什么?
也就是我们所说的主从复制,主机数据更新后根据配置和策略, 自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
4.2能干嘛?
读写分离
容灾恢复
4.3怎么玩?
4.3.1配从(库)不配主(库)
4.3.2从库配置:slaveof 主库IP 主库端口
每次与master断开之后,都需要重新连接,除非你配置进redis.conf文件
4.3.3修改配置文件细节操作
拷贝多个redis.conf文件
使用cp 命令拷贝文件
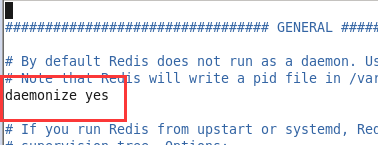
 开启daemonize yes
开启daemonize yes
 pid文件名字
pid文件名字
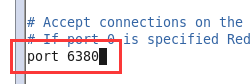
 指定端口
指定端口
 log文件名字
log文件名字
 dump.rdb名字
dump.rdb名字

4.3.4常用命令
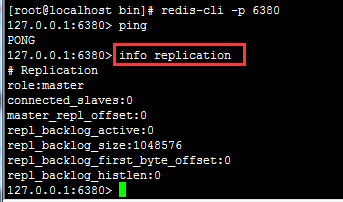
info replication(查看当前服务)
 slaveof 127.0.0.1 6379(从服务连接主服务)
slaveof 127.0.0.1 6379(从服务连接主服务)

4.3.5常用三招
一主二仆(从服务通过slaveof连接主服务)
主机不变,两台从机连接主机slaveof 127.0.0.1 6379 每次与master断开之后,都需要重新连接,除非你配置进redis.conf文件
 薪火相传
薪火相传
主机不变,一台从机连接主机,另一台从机连接一台从机
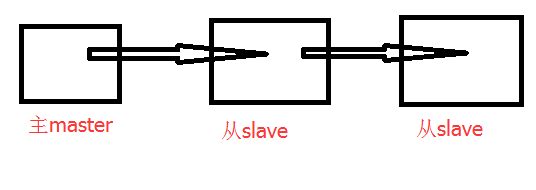 反客为主
反客为主
slaveof on one(使当前库为master)
4.3.6复制原理
slave启动成功连接到master后会发送一个sync命令 Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步 全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。 增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步 但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
4.3.7哨兵模式(sentinel)-反客为主自动版
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
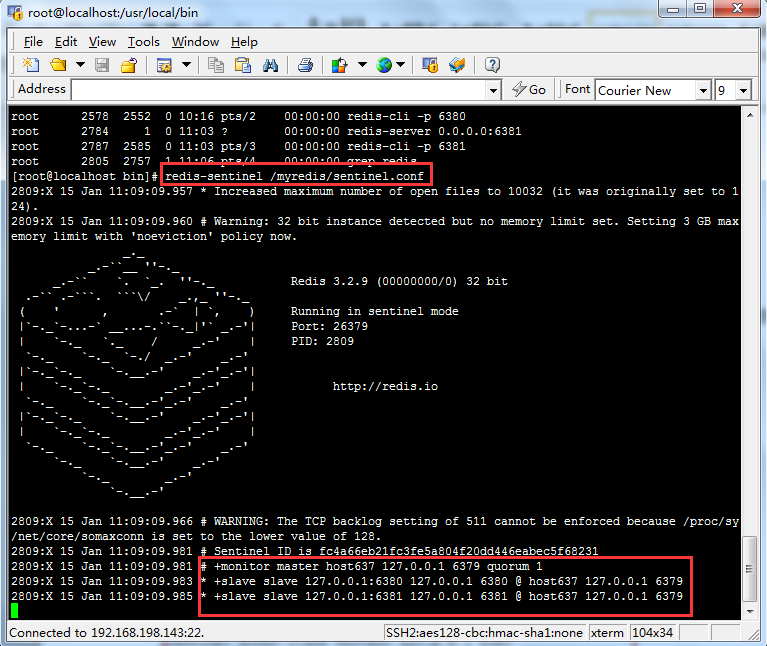
新建sentinel.conf
sentinel monitor 被监控的主机名字(自己起名字) 127.0.0.1 6379 1
最后一个1表示主机挂了,所有slave投票,谁的票数多于1票,该slave为master

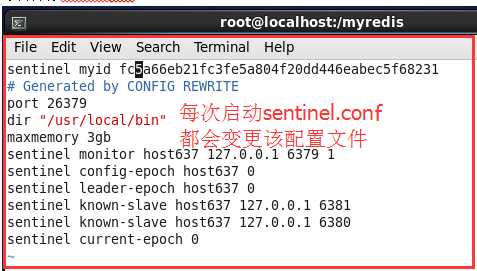
每次启动sentinel.conf都会变更文件内容
 启动redis-sentinel /myredis/sentinel.conf 哨兵服务后,shutdown原来的master,稍等片刻,查看哨兵服务后台,会有不到一分钟的延时,然后确认现在的master服务。
启动redis-sentinel /myredis/sentinel.conf 哨兵服务后,shutdown原来的master,稍等片刻,查看哨兵服务后台,会有不到一分钟的延时,然后确认现在的master服务。

4.3.8复制的缺点
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重
Linux



评论